Ready To Grow Your Startup?
Hey, we are Growth Hackers. See our thoughts, stories and ideas.
Sign up for our newsletter where the experts reveal their secrets on startup growth.
Join 17,212+ Growth Hackers and Marketers who work at companies like:
Episodes
Are you an entrepreneur who is trying to grow a startup? We have over 100 episodes
where the experts on
startup growth reveal their secrets.

26 Simple Websites
Most people go through their lives without ever actualizing a million-dollar idea. When you ask folks, they often say they just don’t have the smar...

Maximizing Product Value:
I sat with Clay Collins, CEO at Nomics and formerly CEO at Leadpages, to talk about how to add product value above and beyond what the market alrea...

Discover the Power
Ryan is behind Capitalism.com and the Freedom Fastlane Podcast. In this interview, we dive into his unique ideas around building a thriving communi...

The Webinar Magic
Wilco de Kreij is the founder UpViral. He is a full-time online marketing “whiz kid” who started at the age of 16, when he started selling sunglass...

Fueling Your Data
Data is the new oil. Unfortunately, data science is not something easy to learn. In this episode, I spoke with Martijn, CoFounder of DataCamp, the ...

The Secrets of
Jason Swenk has been an entrepreneur as far back as he can remember. It started at age 12 when he began pulling sunken golf balls out of the pond a...

The Art of
Nathan Latka is the principal of Latka Capital; executive producer and host of The Top Entrepreneurs podcast; and CEO at two companies he's recentl...

Discover Brian Kidwell’s
Brian is the Growth Marketer over at Scott's Cheap Flights. My co-founder Mike raves about the service and noticed how fast it was gaining populari...

GHTV Exclusive: Vincent
Vincent Dignan has launched two websites that get over a million visitors a month, was accepted into Techstars, and was voted best talk at SXSW 201...

Learn How to
Brennan Dunn has created an empire helping freelancers. Unfortunately in this episode Bronson forgot to plug in the correct mic and the audio is at...
Recipes
Discover More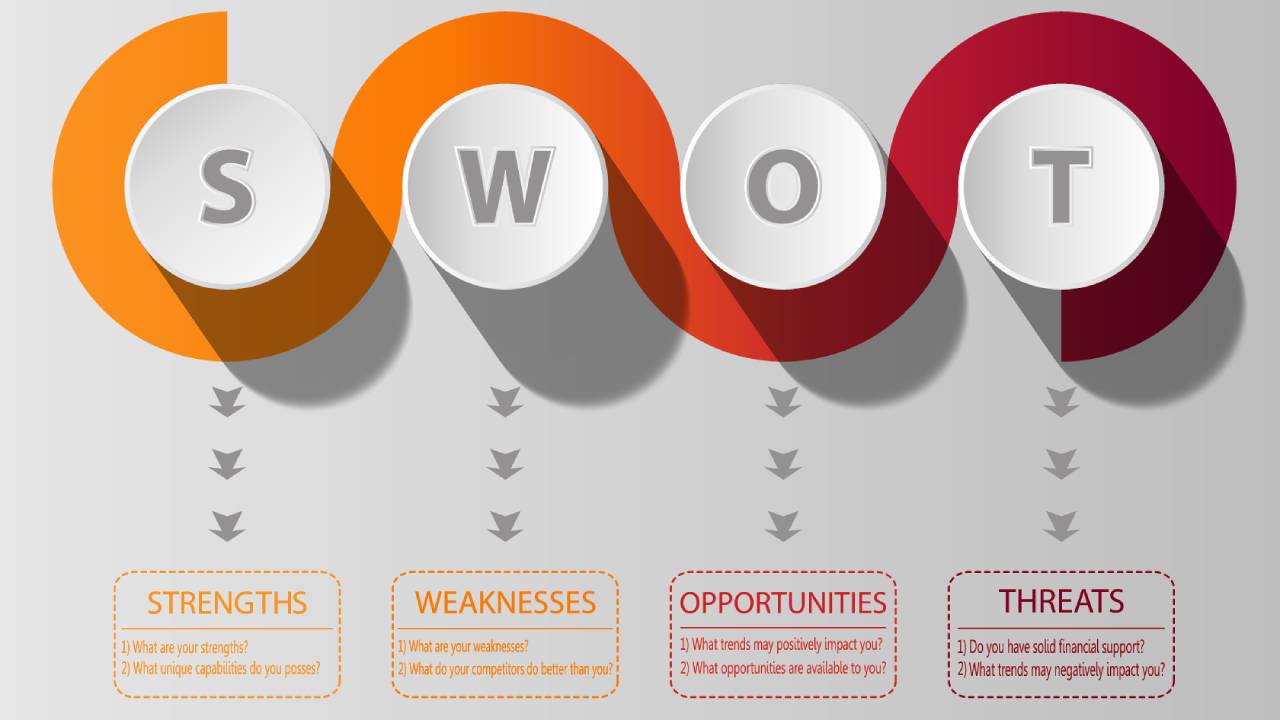
SWOT Bot? 🤖
Yeah, SWOT Bot. ...

Growth Hack Hall
Red Bull has pulled some of the most memorable marketing stunts of the 21st century. Maybe you've seen the

5 Critical Personalization
One source I’ve been paying attention to recently is Exploding Topics, whose data-driven analysis "casts a wide net" to "find trends before they’re...

Why Should You
When I’m wondering whether a topic’s worth talking about, there are two easy criteria I turn to. Either 1) everyone’s talking about it, or 2) a few...

Legendary Hacks: The
Say what you will about AirBnB, but they’ve earned their place in the start-up hall of fame. For real, no doubt. And they wouldn’t have achieved th...
Has To Say
Membership is a no-brainer. They deliver actionable content, resources, and a supportive community.

The quality and guest lineup can't be beat, recommend for any startup acquiring users

Most online marketers are, quite frankly, full of it. They only know how to teach marketing, not how to actually sell a real thing. GHTV teaches you the 'how', and best of, without the bullshit.

A great resource for anyone looking to get on the inside track on the trends and thinkers who are reinventing the marketing game.

Anyone who wants to learn the principles of growth hacking and how to grow a business should be using this resource.

Great info, actionable stuff, can't say enough about the quality of this site for startups

GHTV is a fantastic way to learn from some of the best in the business." - Nir Eyal, bestselling author of "Hooked: How to Build Habit-Forming Products

I can't think of a better resource and lineup than what these guys have put together when it comes to growth hacking.

I wish I had this resource when first starting out, it would have accelerated the learning curve exponentially
